Monitoring
In order to monitor your Anka Build Cloud, you’ll need a few things:
A way to visualize information and setup alerts. We recommend Grafana.
A way to collect and aggregate logs. We recommend Loki.
A way to collect metrics (time series database, etc). We recommend Prometheus.
Grafana
Start with reading over and performing the steps in the Setup Grafana documentation.
Once setup, you can use our example dashboard json as a starting place for your own. You will need Prometheus and Loki setup for that. Read about those below.
Grafana will need to connect to the host and port for Prometheus. This is available at http://host.docker.internal:8095 if you used the scripts in the Getting Started repo.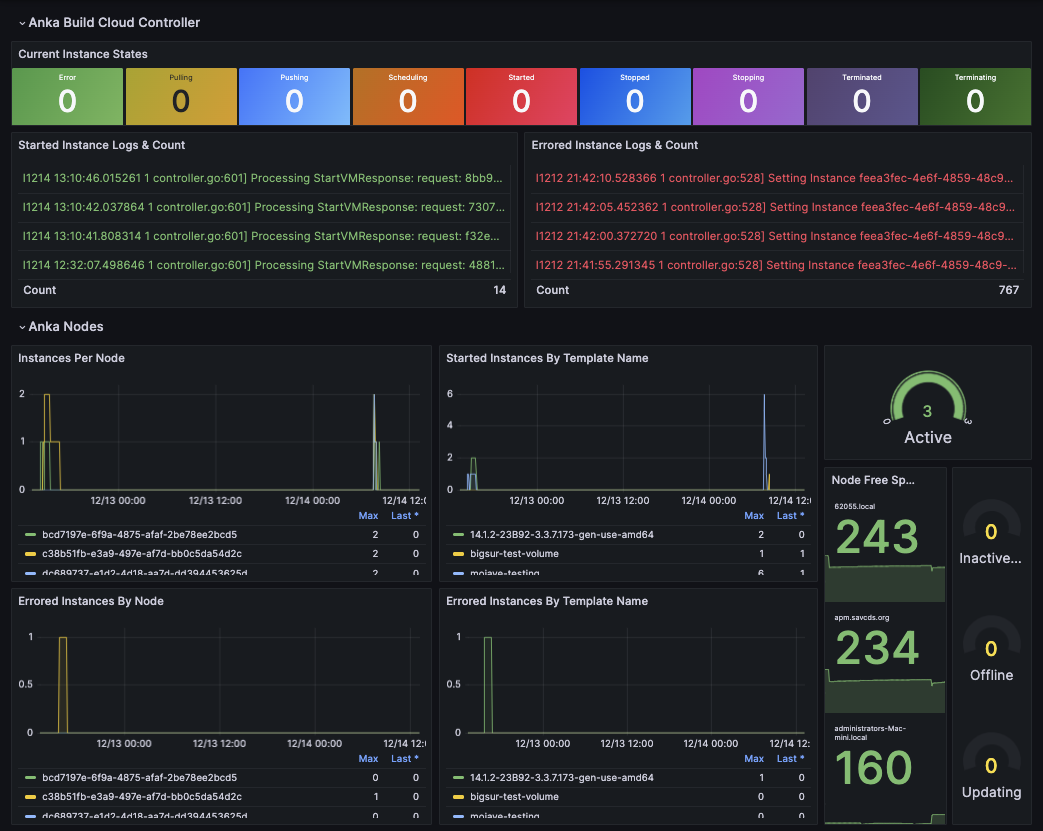
Important
- Instances in a Scheduling state will transfer to Terminating for 1 minute until they disappear. There is no Terminated state for an Instance that hasn’t started. This can cause Terminating and Terminated to not match up and cannot be relied upon.
Prometheus
Release Notes can be found on the official Github repo.
Prometheus is a powerful monitoring and alerting toolkit. You can use it to store Anka Controller, Registry, and VM metrics to build out or integrating into existing graphing tools like Grafana.
While exactly how you should install Prometheus and Grafana are outside of our bounds of support, we do have a way to set it up locally (using docker), connect it to your Build Cloud Controller, and start playing around on your machine. The script you can run to achieve this can be found on our Getting Started Github Repo. Alternatively, the full documentation can be found here: https://grafana.com/docs/grafana/latest/getting-started/getting-started-prometheus/.
Once the getting-started repo is cloned into your local machine, you need to start a docker container with Prometheus. Execute the run in docker script: cd getting-started && ./PROMETHEUS/run-prometheus-on-docker.bash. Once running, visit the url and port it created for you (shown in the output of the script).
Prometheus does not collect metrics from the Anka Build Cloud by default. You’ll need to run the Anka Prometheus Exporter for that. Use the Getting Started Github Repo script for this:
❯ ./PROMETHEUS/install-and-run-anka-prometheus-on-mac.bash
]] Removing previous files and processes
]] Downloading anka-prometheus-exporter from github
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 193 100 193 0 0 1331 0 --:--:-- --:--:-- --:--:-- 1331
100 656 100 656 0 0 2429 0 --:--:-- --:--:-- --:--:-- 2429
100 6614k 100 6614k 0 0 7440k 0 --:--:-- --:--:-- --:--:-- 7440k
Archive: anka-prometheus-exporter_v2.1.0_darwin_amd64.zip
inflating: anka-prometheus-exporter
]] Running /tmp/anka-prometheus-exporter --controller-address http://anka.controller and backgrounding the process
================================================================
PID: 2323
Endpoint URL: anka.prometheus:2112
❯ {"level":"info","msg":"Starting Prometheus Exporter for Anka (2.1.0)","time":"2021-03-22T15:19:17-04:00"}
{"level":"info","msg":"Serving metrics at /metrics and :2112","time":"2021-03-22T15:19:17-04:00"}
This will run the exporter in the background (it will not be available after you reboot your machine and you’ll have to re-run the script). The exporter is setup, by default, to connect to http://anka.controller and your controller may not be running at this URL and port. Feel free to modify the script!
Next, you’ll want to confirm that the metrics are now available in Prometheus.
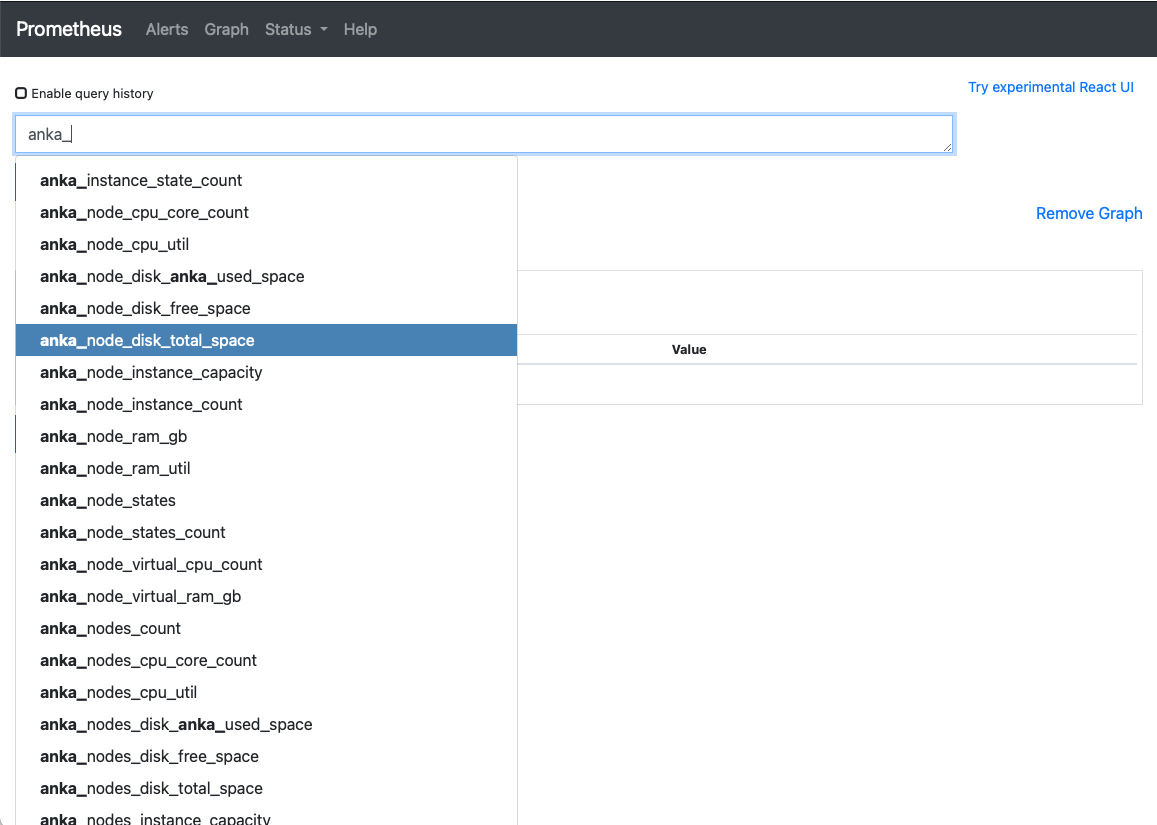
Once you’ve confirmed the metric are available, you can now use the built in graph and alerting for several metrics. For example: anka_node_states to see when Node connectivity to the controller fails, anka_instance_state_count to see when instances are throwing errors, anka_node_cpu_util to trigger alarms when VMs are crippling the Node, and much more. A full list of metrics is available at https://github.com/veertuinc/anka-prometheus-exporter#exposed-metrics.
If you’re running Grafana through docker-compose.yml instead, you can use something like this. Note that Grafana loads in the datasources through the entrypoint which we will need later on:
version: "3.6"
networks:
grafana:
services:
grafana:
image: grafana/grafana
container_name: grafana
depends_on:
- anka-prometheus-exporter
environment:
- GF_PATHS_PROVISIONING=/etc/grafana/provisioning
entrypoint:
- sh
- -euc
- |
mkdir -p /etc/grafana/provisioning/datasources
cat <<EOF > /etc/grafana/provisioning/datasources/ds.yaml
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus:9090
- name: Loki
type: loki
access: proxy
orgId: 1
basicAuth: false
version: 1
url: http://loki:3100
EOF
/run.sh
ports:
- 80:3000
volumes:
- "/home/ec2-user/grafana.ini:/etc/grafana/grafana.ini"
- "/home/ec2-user/grafana-data/:/var/lib/grafana/"
healthcheck:
test: [ "CMD-SHELL", "wget --no-verbose --tries=1 --spider http://localhost:3000/api/health || exit 1" ]
interval: 10s
timeout: 5s
retries: 5
networks:
- grafana
prometheus:
image: prom/prometheus:v2.48.0
container_name: prometheus
restart: always
command:
- '--config.file=/mnt/prometheus.yml'
- '--web.enable-admin-api'
- '--web.enable-lifecycle'
ports:
- "9090:9090"
volumes:
- "/home/ec2-user/prometheus.yml:/mnt/prometheus.yml"
- "/home/ec2-user/prometheus-state:/prometheus"
networks:
- grafana
anka-prometheus-exporter:
image: veertu/anka-prometheus-exporter:latest
container_name: anka-prometheus-exporter
depends_on:
- prometheus
ports:
- "2112:2112"
volumes:
- "/home/ec2-user/:/mnt/"
environment:
ANKA_PROMETHEUS_EXPORTER_TLS: "true"
ANKA_PROMETHEUS_EXPORTER_CONTROLLER_ADDRESS: "https://controller.mydomain.com"
ANKA_PROMETHEUS_EXPORTER_CLIENT_CERT: "/mnt/crt.pem"
ANKA_PROMETHEUS_EXPORTER_CLIENT_CERT_KEY: "/mnt/key.pem"
networks:
- grafana
Loki
We’ll attach Loki by adding the service to our grafana docker-compose.yml:
version: "3.6"
networks:
grafana:
services:
grafana:
. . .
loki:
image: grafana/loki:2.9.3
depends_on:
- prometheus
ports:
- "3100:3100"
command: -config.file=/etc/loki/local-config.yml -print-config-stderr
volumes:
- /home/ec2-user/loki-storage:/tmp/loki
- /home/ec2-user/loki-config.yml:/etc/loki/local-config.yml
networks:
- grafana
In your loki-config.yml, add:
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 127.0.0.1
path_prefix: /loki
storage:
filesystem:
chunks_directory: /loki/chunks
rules_directory: /loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v12
index:
prefix: index_
period: 24h
ruler:
alertmanager_url: http://localhost:9093
Collecting Controller & Registry Logs
Next, you’ll need to setup promtail to capture the logs from the Anka Build Cloud containers. On the same server that our Anka Build Cloud Controller & Registry is running, create a new docker-compose.yml with:
version: "3.6"
services:
promtail:
image: grafana/promtail:2.9.0
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /home/ubuntu/promtail/config.yml:/etc/promtail/config.yml:ro
command: -config.file=/etc/promtail/config.yml
Then create config.yml and change the URL to match your grafana/loki URL:
---
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://grafana.mydomain.com:3100/loki/api/v1/push
tenant_id: tenant1
scrape_configs:
- job_name: flog_scrape
docker_sd_configs:
- host: unix:///var/run/docker.sock
refresh_interval: 5s
relabel_configs:
- source_labels: ['__meta_docker_container_name']
regex: '/(.*)'
target_label: 'container'
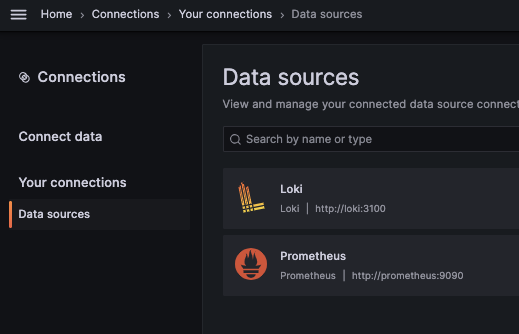
You should now see the Loki datasource:
Collecting Agent logs
Using promtail to collect and send logs to Loki is fairly easy. We should be seeing logs for the Controller, Registry, and ETCD, but we need to collect the logs for the Anka nodes too.
Since the node is macOS, installation is not done through docker.
Install
promtailwith brew:brew install promtail.Edit
/usr/local/etc/promtail-local-config.yaml, adding the following, and editingmyHostnameand thegrafana.mydomain.com:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://grafana.mydomain.com:3100/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: myHostname
__path__: /var/log/veertu/*.INFO
pipeline_stages:
- multiline:
firstline: '^{'
lastline: '^}'
max_wait_time: 3s
- json:
expressions:
output_field: message
- Then start the service
brew services start promtail.
You can now query for job equaling your hostname for the machine and the filename /var/log/veertu/anka_agent.INFO.
Understanding Logs
The Anka Build Cloud agent attempts to retry failures, however, it’s still a good idea to look for certain types of errors occurring in your setup and handle them before they become larger problems. We’re going to walk you through where important logs are found and then what to look for and trigger alerts on.
Nodes
On your Anka Nodes runs the Controller Agent, handling communication to the Anka Build Cloud. This agent logs to /var/log/veertu.
- Logs location:
/var/log/veertu - Format:
regd.HOSTNAME.USER.LOG.LOGTYPE.TIMESTAMP
There are 5 type of symlinks in the logs location pointing to the latest active logs. The verbosity of the logs are from highest (INFO) to the lowest (ERROR):
anka_agent.INFO- contains all of the below except for CMD log.anka_agent.WARNING- contains WARNNIGS & ERRORS.anka_agent.ERROR- contains just ERRORS.anka_agent.FATAL- only FATAL ERRORS.anka_agent.CMD- (new in 1.20.0) contains the various anka commands the agent is executing on the host as well as the returned data.
You can also read and download the logs via the UI in the Controller dashboard. Though, only relevant if you’ve joined your Node to the Build Cloud Controller & Registry.
Node Common Errors
can't start vm
- These errors are thrown at the end of a start VM task attempt by the Node. It’s a generic error and not specific. However, if enough of these are thrown in a short amount of time, you should dig in further.
- Alerts should trigger when more than 3 of these happen in a 20 minute time period.
rejecting due to lack of disk space
- These errors happen when the Node itself can’t handle the amount of disk space needed for the VM template it’s about to pull. This means either 1. your individual VM templates are too large and need to be optimized a bit, and/or 2. your node just doesn’t have enough space for the amount of templates it needs to hold.
- Alerts should trigger when more than 3 of these happen in a 60 minute time period.
- Also, the agent will delete the least used templates one by one from the Node until it has enough space to download. On top of that, the node will not take new tasks while it’s pulling. You can experience a situation where two massive templates that cannot both exists on the host due to their size will cause the node to clean up one to pull the other over and over, all while locking task processing for other unrelated jobs. The Node will be useless while it’s pulling.
Controller
Central to the Anka Build Cloud is the Controller, handling the UI/visual interaction for users, APIs, Queuing of tasks, etc. Behind it is ETCD, handling storage of temporary information used by the Controller.
Error logs are formatted starting with severity as a character: I as Information, W as Warning, and E as Error:
E0501 12:32:30.426698 341 controller.go:114] StartVm: failed to get VM 7141d04e-cb45-46bf-9026-4266d74998d5 from registry
Unless your ETCD is run separately (like in the case of docker), the logs for both services are combined.
Some error are not critical and can be ignored. Feel free to contact support for confirmation of any of these you find.
Docker
Using the docker logs command: docker logs --follow <ControllerContainerName>
The controller is an API, so all API connections made to it from Anka-agent or CI platforms(Jenkins) logs here. If a vm fails to start it suggests first to check this logs.
Mac Package
/Library/Logs/Veertu/AnkaController/anka-controller.INFO
/Library/Logs/Veertu/AnkaController/anka-controller.WARNING
/Library/Logs/Veertu/AnkaController/anka-controller.ERROR
Show logs by command:
sudo anka-controller logs(similar totail -f)There are 4 types of log files, in the snapshot you can see log files without ID, they are LINK files- point to the latest log been created ( the last active vm) , each vm can generate all of the log types below. the robosety of the logs are from highest(INFO) to the lowest(ERROR), you can check this files using ’tail’ command:
anka-controller.INFO- contains ALL logs.anka-controller.WARNING- contains WARNINGS & ERRORS.anka-controller.ERROR- contains just ERRORS.anka_agent.FATAL- Only FATAL ERRORS (both controller and agent).
The mac controller package relies on an internal ETCD database. Logs for ETCD will be included in the controller logs, but by default they are set to be non-verbose.
Controller/ETCD Common Errors
- [etcd]
database space exceeded
- This is detailed in the official documentation.
- You should alert on this immediately. It is a critical error.
Registry
The Registry stores your Anka VM Templates and Tags. It is also responsible for storage of the Centralized Logs (all other components post their logs to it). It is very uncommon to find errors in the logs, but you should still become familiar with where they are.
Docker
- Logs location: Registry storage directory under
files/central-logs.
Using the
docker logscommand:docker logs --follow <RegistryContainerName>.The Registry and Controller logs share the same file and are available under the Controller’s
Logs>Service Name: Controller.
Mac Package
/Library/Logs/Veertu/AnkaRegistry/anka-registry.INFO
/Library/Logs/Veertu/AnkaRegistry/anka-registry.WARNING
/Library/Logs/Veertu/AnkaRegistry/anka-registry.ERROR
Recommended Alerts
- Total Free Capacity across all Nodes is 0 for more than 15 minutes. This typically means you need more Nodes to handle the VM start request load.
- Registry Available Space is less than 70GB. We recommend keeping your Registry free space at 50GB or more.
- Usage of a specific VM Template is 0 over a week period. This usually means that a Template is ready to be deletes as it is no longer used.
Stuck VM Monitoring
Rarely we see certain dependencies installed inside of VMs causing the entire VM to become unresponsive. Unresponsive or “stuck” VMs can run indefinitely and therefore cause CI/CD jobs to run until they hit timeouts. This is a bad experience for users, so we’ve added a feature which constantly checks whether or not the command-line inside of VM is responding to a simple command. If it cannot, the Anka Agent on your Node will fail the VM, causing the CI/CD job to receive a failure and then send a Termination request to the Controller.
You can enable this feature when you join your Node to the Anka Cloud with: sudo ankacluster join --enable-vm-monitor http://anka.controller.
You can see the flags and options with:
❯ ankacluster join --help
Joins the current machine to one or many Anka Build Cloud Controllers
Usage:
ankacluster join CONTROLLER_ADDRESS[,CONTROLLER_ADDRESS2] [flags]
Flags:
...
--enable-vm-monitor Enabled unresponsive VM monitoring. This will throw a failure when the VM becomes unresponsive for longer than the --vm-stuck-timeout
...
--vm-stuck-delay duration The time between unresponsive VM checks (default: 30s - Duration examples: 3500s, 20m, 5h)
--vm-stuck-timeout duration The time to wait until the VM is considered unresponsive (default: 10s - Duration examples: 3500s, 20m, 5h)